My Ex4100 NAS experienced an unclean shutdown due to a power outage. (It was on a UPS and had a signaling cable connected but didn’t shut itself off correct before the battery charge ran out.)
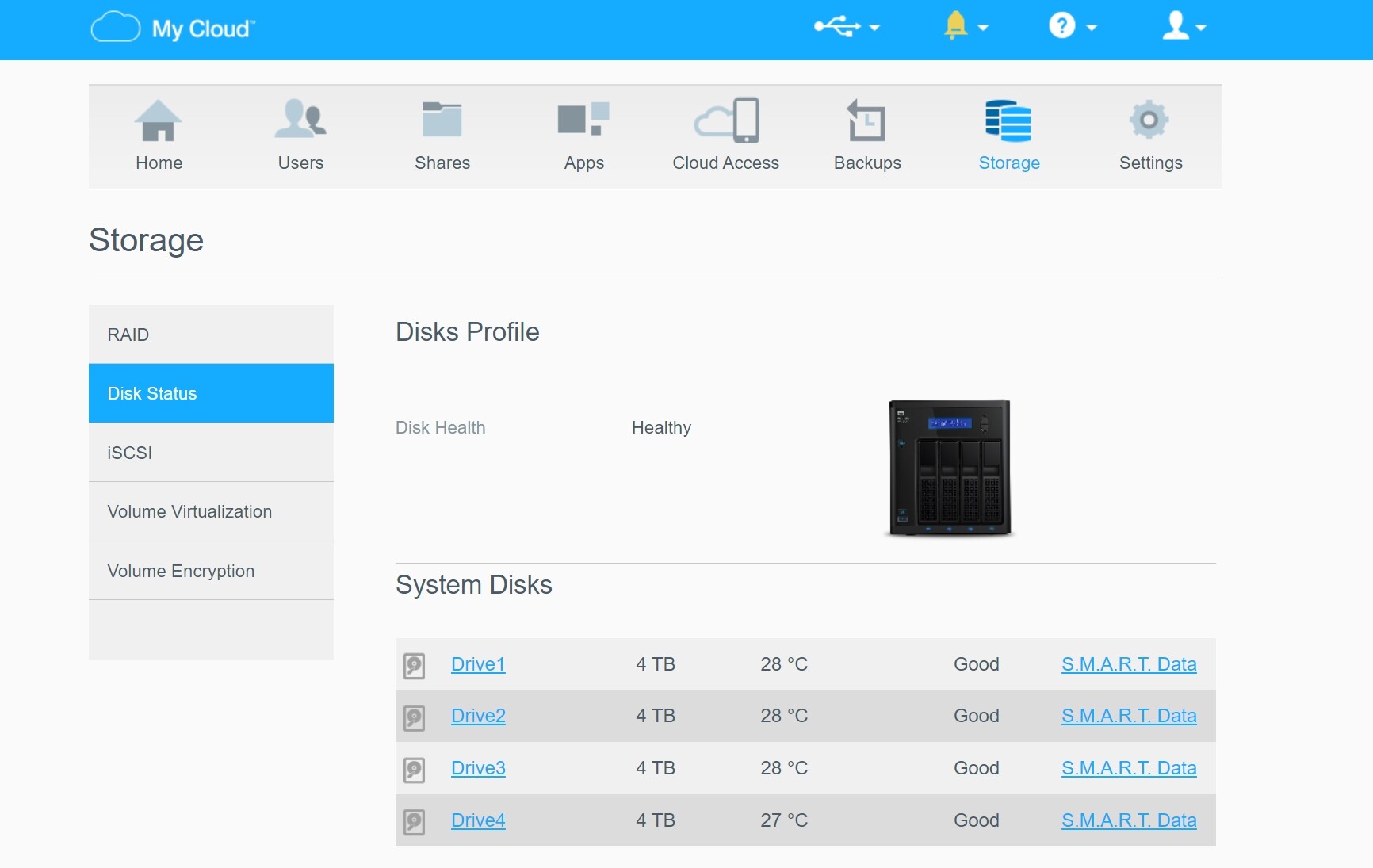
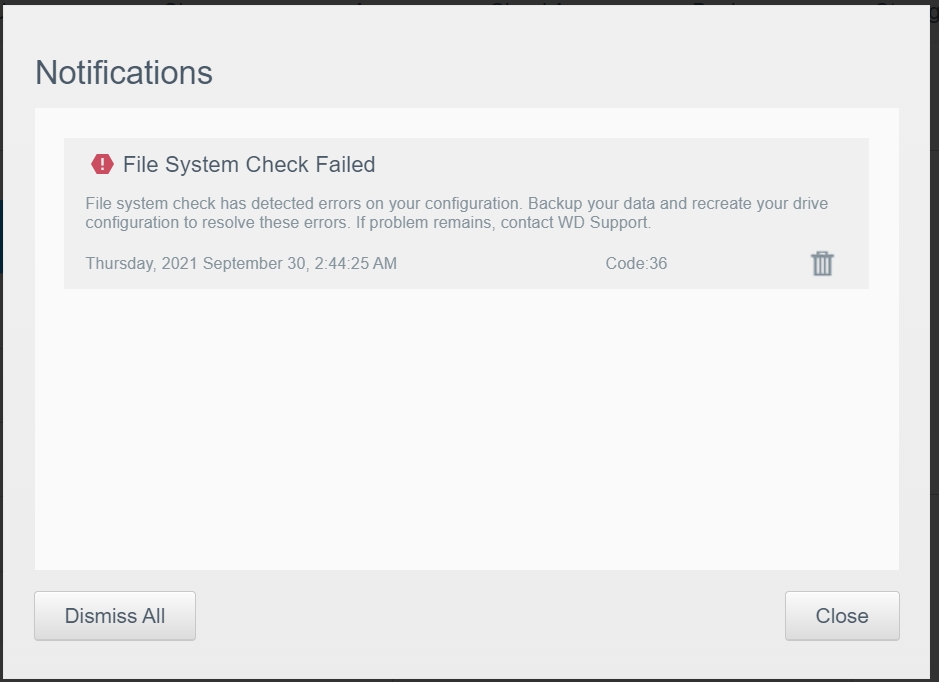
The drives and the RAID volume is accessible, The Disk Test fails.
The issue appears to affect the Public share/folder. The Public share has a Public folder that contains an seemingly endless number of Public subfolders. Which probably explains why the Disk Test fails.
I’ve read numerous articles with instruction for running fsck from the commandline or deleting the Public share, but they all seem to be for other versions of the Mycloud product.
Do anyone have updated instructions for either task?
- Run the fsck command manually on the system to try to fix the file system,
- Unshare or delete the Public share and folder.
I’m familiar with UNIX, but not Busybox or NAS implementations of it.
If you read my post, you will see that the “Disk Test” was run. That was what generated the “Failed” state.
I not sure I’m quite that pessimistic. I’d just like to run fsck on the volume.
If this was UNIX, I would have already fixed it.
Unfortunately, I’m not familiar enough with Busybox to be able to translate the correct commands. Hopefully, someone more familiar with these systems will help me out?
I’ve already unmounted the volume and ran e2fsck. It reports that fsck needs to be run directly.
As for experience: Yes, this is my first WD NAS device. (I chose it over QNAP because of my experience with your harddrives, which I prefer for work or home use.)
Having decades of experience with Windows and UNX servers as well as EqualLogic, NETAPP and PowerEdge storage systems, I was surprised that one unclean shutdown would cause an “unrecoverable” file system error.
If you’re familiar with the firmware, do you know how this can happen?
root@Filer01 root # smartctl --attributes --log=selftest /dev/sda
smartctl version 5.38 [arm-marvell-linux-gnueabi] Copyright (C) 2002-8 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 171 169 021 Pre-fail Always - 6450
4 Start_Stop_Count 0x0032 099 099 000 Old_age Always - 1540
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 085 085 000 Old_age Always - 11114
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 31
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 17
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 1523
194 Temperature_Celsius 0x0022 126 112 000 Old_age Always - 24
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
1 Extended offline Aborted by host 90% 11030 -
2 Extended offline Completed without error 00% 11025 -
3 Short offline Completed without error 00% 11016 -
4 Extended offline Aborted by host 90% 11016 -
5 Short offline Completed without error 00% 10958 -
6 Short offline Completed without error 00% 2 -
7 Short offline Completed without error 00% 2 -
8 Short offline Completed without error 00% 0 -
The Full Test ran overnight. When I logged in the next morning, an alert message reporting that all disks passed. I closed that window without a screen shot:(
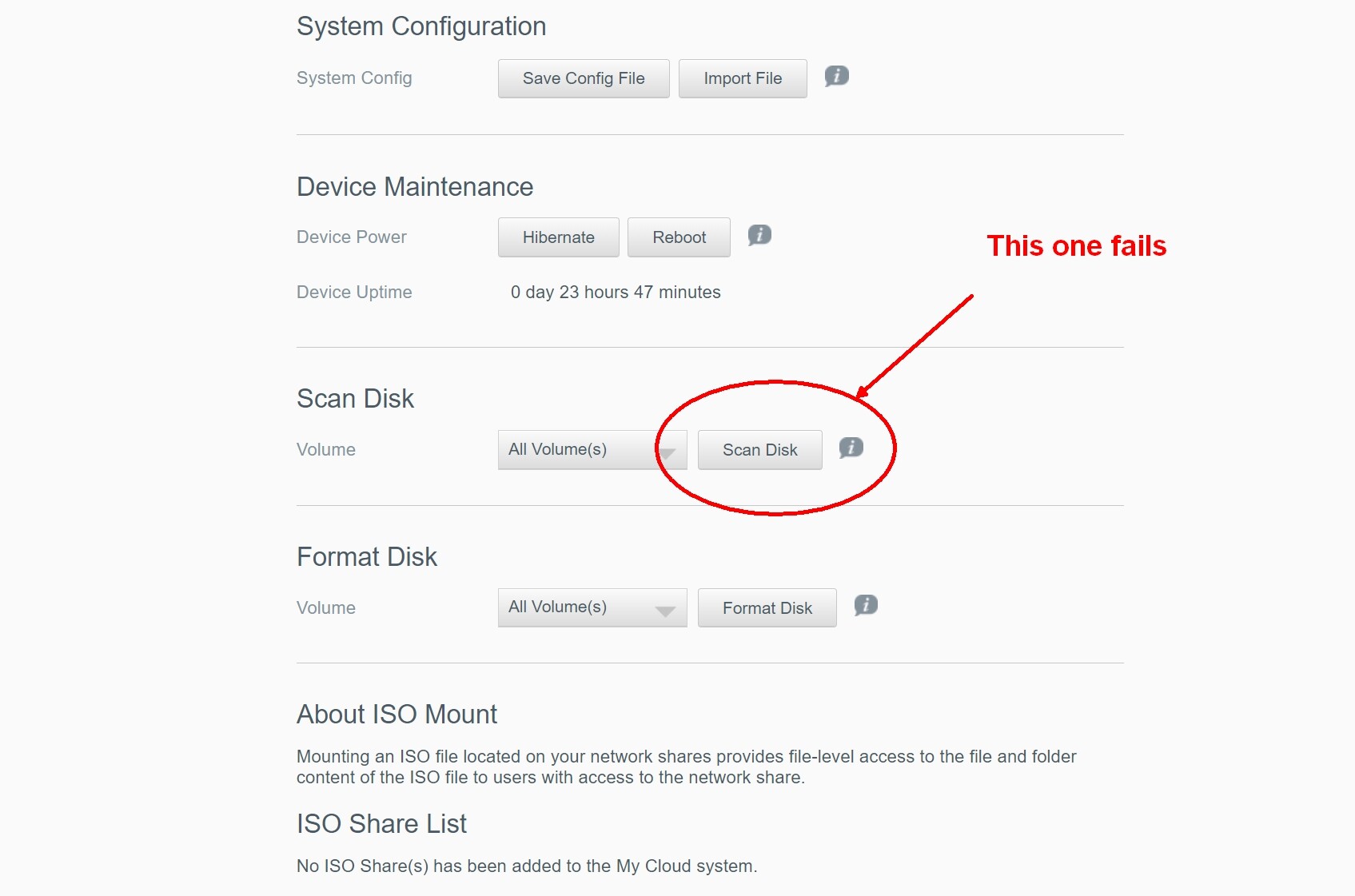
It’s the Scan Disk test that fails.
I already tried that multiple times. I also upgraded the firmware in case it made a difference?
No joy.
I ran this yesterday evening and although it completed and logged it as successful, it didn’t result in the expect condition. The network and user database was reset, but the user shares were left intact, (minus their permissions.)
I plan to try rerunning tonight.
For what it’s worth. Reran the system restore and got the same results. I can still access my files, so I’ll keep it as repository for non-important files. I might also try upgrading to v5 code to see if it can fix this bug.
HA! I read some of the forum posts of other customers who upgraded or attempted to upgrade to v5.x.
I’ll stick with v2.x until I have no other choice.